You can find the final code for this blog post on GitHub .
This is Part 2 of a multipart blog series on Creating a Kotlin Dependency Injection library. Check out other parts of the series below.
How are we going to optimize?
The first thing we need before we start optimizing is data. We need to understand how our current code is performing, and then we can look for potential areas of optimization. My favorite way to do this to profile our code and produce a flame graph. This allows me to see where our code is spending it’s time, and prioritize / identify different places to optimize our app.
Before we get there, we need to create some simple example’s of our app
The Benchmark Samples
I created a SmallExample
(link)
with only five dependencies, and a LargeExample
(link).
Our LargeExample is meant to represent a mature application, and has ~100 dependencies. You can
see its basic structure below.
class LargeExample(
val a: A,
val b: B,
val c: C,
// ... includes the rest
val aa: AA,
val bb: BB,
val cc: CC,
// ... includes the rest
val aaa: AAA,
val bbb: BBB,
val ccc: CCC,
// ... includes the rest
val aaaa: AAAA,
val bbbb: BBBB,
val cccc: CCCC,
// ... includes the rest
val allDependencies: AllDependencies,
) {
companion object {
fun createKinject(): ObjectGraph {
return objectGraph {
singleton { A() }
singleton { B(get()) }
singleton { C(get(), get()) }
// ...
singleton { AA(get(), get()) }
singleton { BB(get(), get()) }
singleton { CC(get(), get()) }
// ...
singleton { AAA(get(), get()) }
singleton { BBB(get(), get()) }
singleton { CCC(get(), get()) }
// ...
singleton { AAAA(get(), get()) }
singleton { BBBB(get(), get()) }
singleton { CCCC(get(), get()) }
// ...
singleton {
LargeExample(
get(), get(), get(), get(), get(), get(), get(), get(), get(), get(), get(), get(),
get(), get(), get(), get(), get(), get(), get(), get(), get(), get(), get(), get(),
get(), get(), get(), get(), get(), get(), get(), get(), get(), get(), get(), get(),
get(), get(), get(), get(), get(), get(), get(), get(), get(), get(), get(), get(),
get(), get(), get(), get(), get(), get(), get(), get(), get(), get(), get(), get(),
get(), get(), get(), get(), get(), get(), get(), get(), get(), get(), get(), get(),
get(), get(), get(), get(), get(), get(), get(), get(), get(), get(), get(), get(),
get(), get(), get(), get(), get(), get(), get(), get(), get(), get(), get(), get(),
get(), get(), get(), get(), get(), get(), get(), get(), get(),
)
}
}
}
}
}Flame Graph
I created a simple JVM application that creates the LargeExample ObjectGraph and injects the
LargeExample a few thousand times, and then profiled it. Here is the resulting flame graph:
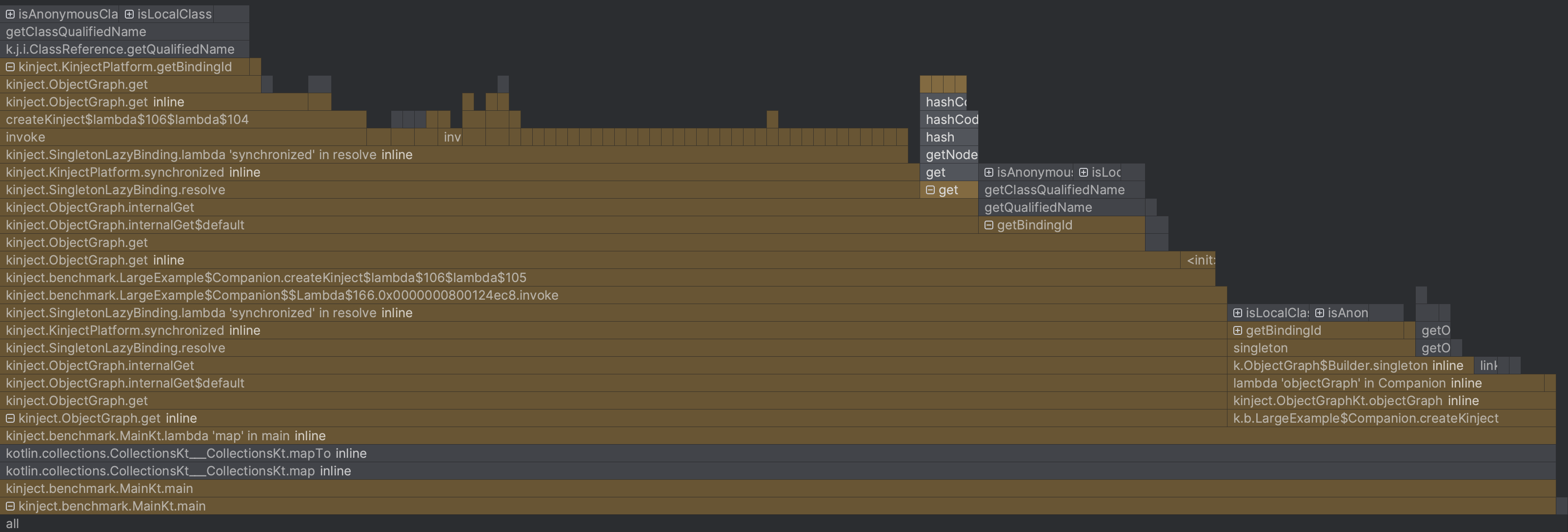
A few thoughts:
- When all the usages of
KinjectPlatform.bindingIdare accounted for, it’s taking 53% of the total execution time. This is a surprise and warrants an investigation. HashMapBindingTable.getaccounts for only 3.74% andHashMapBindingTable.putaccounts for only 0.74%. I get similar results when profiling on a modern Android Device. This is another surprise. On Dalvik and early versions of ART, theBindingTablebased on aHashMapwas a performance bottleneck. Since then, ART has added JIT compilation as well as several memory allocation improvements. When I first made Kinject, I was able to get a ~40% improvement in performance with a custom hashing algorithm; however, it seems very unlikely that I’ll be able to see the same performance improvements by focusing any efforts here, but I’ll investigate this anyway, since it was my original plan for the blog post.
Another thought:
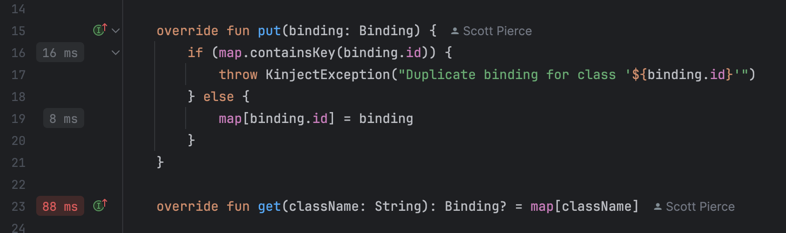
- IntelliJ has outdone itself with this new profiling feature where it puts the time of each function from the last profiling function next to it:
Establishing a Baseline Benchmark
I
benchmarked
our small and large examples using kotlinx.benchmark. I thought it’d be fun to test Kotlin Native
and JS as well, however our primary concern right now is JVM and Android. The Android benchmark was
run on an android device, while all other benchmarks were run on my M1 Macbook Pro.
The below data are throughput benchmarks. The values are read in how many times per second they can run. Bigger is Better.
| Test | JVM (op/s) | Native (op/s) | JS (op/s) | Android (op/s) |
|---|---|---|---|---|
| Create - Small | 1,323,356 | 998,996 | 1,900,810 | 434,216 |
| Create - Large | 70,821 | 61,121 | 129,972 | 17,881 |
| Inject - Small | 8,225,443 | 7,293,272 | 17,441,115 | 157,555 |
| Inject - Large | 8,365,753 | 6,904,752 | 17,821,270 | 4,382 |
It’s odd to see JVM performing worse than JS. I suspect this is somehow related to the issue we
found with KinjectPlatform.bindingId taking up 53% of our CPU time.
Optimizing the KinjectPlatform.bindingId Bottleneck
Here is our current code:
actual val KClass<*>.bindingId: String
get() = this.qualifiedName ?: error("No qualified name found for '$this'")We’re using the KClass instead of the Java Class object. It’s possible that the KClass is using
reflection under the hood, and isn’t properly caching the result. Let’s try moving to the standard
java class:
actual val KClass<*>.bindingId: String
get() = this.java.nameHere are the improvements in the benchmark. Bigger is better.
| Test | Original JVM (op/s) | Original Android (op/s) | Optimized bindingId JVM (op/s) | Optimized bindingId Android (op/s) |
|---|---|---|---|---|
| Create ‑ Small | 1,323,356 | 434,216 | 13,393,750 (+912%) | 1,745,200 (+301%) |
| Create ‑ Large | 70,821 | 17,881 | 502,348 (+609%) | 51,044 (+185%) |
| Inject ‑ Small | 8,225,443 | 157,555 | 353,704,703 (+4,200%) | 781,250 (+396%) |
| Inject ‑ Large | 8,365,753 | 4,382 | 345,034,844 (+4,024%) | 14,122 (+222%) |
The improvement from this small change is staggering. Further benchmarking and profiling of
KClass.qualifiedName reveals that it is doing several allocations under the hood, and is likely
using some form of reflection. I assumed that KClass.qualifiedName was delegating to the Java
Class.name. Clearly, that’s not the case.
Optimizing the BindingTable
On Dalvik and early versions of ART, the BindingTable based on a HashMap was a performance
bottleneck. I was able to get a significant 35-40% performance improvement by creating a custom
hashing algorithm like I’ve done below:
I’ve tried replicating my results from years ago by trying improvements, like trying the murmur
hashing algorithm, or moving from linear probing to quadratic probing. I’m still not finding
anything that is able to compete with HashMap’s performance now. I haven’t found any information
about it, but I expect advanced optimizations, like bytecode manipulation, have been done to HashMap
that this blog post simply won’t be able to compete with. If anyone has any information about this,
please reach out. I’d be very interested.
Further Optimizations
Since BindingTable is just wrapping a Map now, the BindingTable can be replaced with Map
instead. This isn’t really necessary, but it allows us to allocate directly to a MutableMap,
instead of creating a List of Bindings and then moving them to the BindingTable, that should
help us with creation time. With Kotlin Native, I’ve noticed performance improvements in the past
when using concrete classes over interfaces. If that’s still true, we should see some improvements
for Kotlin Native as well.
Here is our new ObjectGraph:
class ObjectGraph private constructor(
private val bindings: Map<String, Binding>,
) {
inline fun <reified T : Any> get(): T = get(T::class)
fun <T : Any> get(clazz: KClass<T>): T = internalGet(clazz.bindingId)
@Suppress("UNCHECKED_CAST")
private fun <T : Any> internalGet(className: String, tag: String? = null): T {
val binding = bindings[className]
?: throw BindingNotFoundException("Binding not found for class '$className'")
return binding.resolve(this) as T
}
class Builder {
private val bindings: MutableMap<String, Binding> = HashMap()
fun add(objectGraph: ObjectGraph) {
bindings.putAll(objectGraph.bindings)
}
inline fun <reified T : Any> singleton(
noinline provider: ObjectGraph.() -> T,
): Unit = singleton(T::class, provider)
fun <T : Any> singleton(
clazz: KClass<T>,
provider: ObjectGraph.() -> T,
) {
val bindingId = clazz.bindingId
bindings[bindingId] = SingletonLazyBinding(bindingId, provider)
}
fun <T : Any> singleton(
instance: T,
bindType: KClass<*> = instance::class,
) {
val bindingId = bindType.bindingId
bindings[bindingId] = SingletonBinding(bindingId, instance)
}
fun build(): ObjectGraph {
return ObjectGraph(bindings)
}
}
}And here are our results from this change. Bigger is better:
| Test | Original JVM (op/s) | Optimized bindingId JVM (op/s) | Replace BindingTable for HashMap JVM (op/s) | Overall JVM Improvement |
|---|---|---|---|---|
| Create ‑ Small | 1,323,356 | 13,393,750 (+912%) | 29,579,614 (+120%) | 2135% |
| Create ‑ Large | 70,821 | 502,348 (+609%) | 531,671 (+6%) | 651% |
| Inject ‑ Small | 8,225,443 | 353,704,703 (+4,200%) | 416,290,951 (+18%) | 4961% |
| Inject ‑ Large | 8,365,753 | 345,034,844 (+4,024%) | 412,224,559 (+19%) | 4828% |
The improved performance while creating an ObjectGraph was expected. The improved performance
during injection was not. Since the binding table was really just a thin wrapper around the
HashMap, I assumed that the JIT would be able to optimize it almost completely away. Clearly,
that’s not the case.
In Conclusion
I came into this blog post with confidence that we’d be able to improve the performance of the library, and we did, but not in the way I thought we were going to. I suppose that really just emphasizes the importance of profiling and testing, and how much potential there is to improve our code with a small amount of effort.
I’ll close by comparing our final result, against Koin, another DI library with a similar API surface:
| Test | Kinject JVM (op/s) | Koin JVM (op/s) | Kinject JS (op/s) | Koin JS (op/s) | Kinject Native (op/s) | Koin Native (op/s) |
|---|---|---|---|---|---|---|
| Create ‑ Small | 29,579,614 | 24,370 | 3,055,587 | 23,831 | 1,220,062 | 19,938 |
| Create ‑ Large | 531,671 | 1,326,393 | 94,156 | 360,685 | 61,402 | 267,714 |
| Inject ‑ Small | 416,290,951 | 15,016,114 | 17,612,318 | 5,664,868 | 24,929 | 5,368,693 |
| Inject ‑ Large | 412,224,559 | 15,225,397 | 16,959,762 | 5,259,760 | 6,769,108 | 5,460,421 |
I’m not surprised that our performance is better than Koin, since Koin offers a much broader feature set. Kinject’s features would have to be expanded to have an apples to apples comparison.
A final thought: While this level of performance gain can seem extremely impactful when looking at them side by side like this, we’re talking about fractions of a millisecond in most real world cases. Koin will still be my go-to library for dependency injection in the meantime, simply because of its expanded feature set, and fantastic community support.
You can find the final code for this blog post on GitHub .
This is Part 2 of a multipart blog series on Creating a Kotlin Dependency Injection library. Check out other parts of the series below.